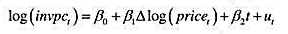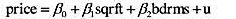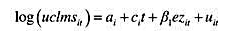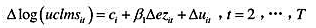含了所观测到的数据,其中个人基本上是自己决定是否参加工作培训。数据集包含同一时期的数据。
(i)在数据集JTRAIN2.RAW中,男人参加工作培训的比例是多大?在JTRAIN3.RAW中的比例又是多大?你认为为什么存在这么大的差距?
(ii)利用JTRAIN2.RAW,做re78对train的简单回归。参与工作培训对真实工资的估计影响有多大?
(ii)现在,在第(ii)部分的回归中增加控制变量re74,re75,educ,age,black和hisp。工作培训对re78的估计影响变化大吗?何以至此?(提示:记得这些都是实验数据。)
(iv)利用JTRAIN3.RAW中的数据做第(ii)部分和第(iii)部分的回归,只报告train的估计系数及其:统计量。现在,控制额外因素的影响如何?为什么?
(v)定义avgre=(re74+re75)/2。求这两个数据集中的样本均值、标准差、最小值和最大值。这些数据集代表了1978年同样的总体吗?
(vi)在数据集JTRAIN2.RAW中,几乎96%的男性的avgre低于10000美元。只利用这些男性的数据,做re78对train,re74,re75,educ,age,black和hisp的回归,并报告培训估计值及其:统计量。对JTRAIN3.RAW
也只利用avgre ≤10的男性做同样的回归。就这个低收入男性子样本而言,实验数据集和非实验数据集估计的培训效应有何差别?
(vii)现在,只针对1974年和1975年失业的男性,利用每个数据集做re78对train的简单回归。培训的估计值又有何差别?
(viii)利用你前面的回归结果,试讨论在比较实验估计值和非实验估计值的背后,拥有可比较总体的潜在重要性。
 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)

 如果结果不匹配,请 联系老师 获取答案
如果结果不匹配,请 联系老师 获取答案

 更多“某企业使用ADS做数据分析,其中部分数据来源于Maxcomp…”相关的问题
更多“某企业使用ADS做数据分析,其中部分数据来源于Maxcomp…”相关的问题
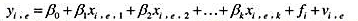

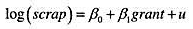
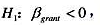 它在5%的显著性水平上统计显著吗?
它在5%的显著性水平上统计显著吗?