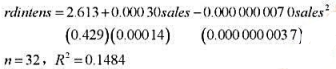题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[主观题]
使用CRIME4.RAW。 (i)在数据集中增加每个工资变量的对数,然后用一阶差分估计模型。问这些变量的
使用CRIME4.RAW。 (i)在数据集中增加每个工资变量的对数,然后用一阶差分估计模型。问这些变量的
使用CRIME4.RAW。
(i)在数据集中增加每个工资变量的对数,然后用一阶差分估计模型。问这些变量的引入如何影响教材例13.9中那些司法变量的系数?
(ii)第(i)部分中的工资变量全部都有预期的符号吗?它们是联合显著的吗?试解释。
查看答案

 如果结果不匹配,请 联系老师 获取答案
如果结果不匹配,请 联系老师 获取答案

 更多“使用CRIME4.RAW。 (i)在数据集中增加每个工资变量…”相关的问题
更多“使用CRIME4.RAW。 (i)在数据集中增加每个工资变量…”相关的问题