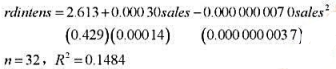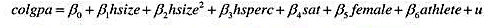题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[主观题]
这个学术搜索系统以数以十亿计的海量元数据为基础,利用数据仓储、资源整合、知识挖掘、数据分析、文
献计量学模型等相关技术,较好地解决了复杂异构数据库群的集成集合,实现高效、精准、统一的学术资源搜索,进而通过分面聚类、引文分析、知识关联分析等实现高价值学术文献发现、纵横结合的深度知识挖掘、可视化的全方位知识关联。 这段广告的语言风格是________。
A.准确细致
B.浑厚雄壮
C.诘屈聱牙
D.华美绚丽
查看答案

 如果结果不匹配,请 联系老师 获取答案
如果结果不匹配,请 联系老师 获取答案

 更多“这个学术搜索系统以数以十亿计的海量元数据为基础,利用数据仓储…”相关的问题
更多“这个学术搜索系统以数以十亿计的海量元数据为基础,利用数据仓储…”相关的问题