 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[主观题]
字符串t和p的长度分别为m和n.t的后缀数组为sa.请说明如何利用t的后缀数组搜索给定字符串p在t中出现的所有位置.要求算法在最坏情况下的时间复杂性为O(mlogn).
查看答案

 如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
如果结果不匹配,请 联系老师 获取答案
 更多“字符串t和p的长度分别为m和n.t的后缀数组为sa.请说明如…”相关的问题
更多“字符串t和p的长度分别为m和n.t的后缀数组为sa.请说明如…”相关的问题
设主串t和模式串p分别是由d(d≥2)元字符集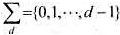 中随机字符组成的长度为n和m的字符串.试证明简单子串搜索算法所做比较次数的期望值为
中随机字符组成的长度为n和m的字符串.试证明简单子串搜索算法所做比较次数的期望值为
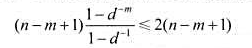
由此可见,对于随机选取的字符串,简单子串搜索算法还是十分有效的.
在模式枚举(pattern enumeration)类应用中,需要从主串T中找出所有的模式串P(T|=n,|P|=m),而且有时允许模式串的两次出现位置之间相距不足m个字符。
类似于教材310页图11.3中的实例,比如在“000000”中查找“000”。若限制多次出现的模式串之间至少相距|P|=3个字符,则应找到2处匹配;反之,若不作限制,则将找到4处匹配。
a)试举例说明,若采用后一约定,则教材11.4.3节BM算法的好后缀策略,可能需要Ω(nm)时间;
b)试针对这一缺陷改进好后缀策略,使之即便在采用后一约定时,最坏情况下也只需线性时间。
问题描述:基因序列是用字符串表示的携带基因信息的DNA分子的一级结构.基因序
列的字符集是Σ={A,C,G,T}.其中字符分别代表组成DNA的4种核苷酸:腺嘌呤、胞嘧啶、鸟嘌呤、胸腺嘧啶.许多疾病往往是由基因突变引起的.这种基因突变是从一个正常的基因序列通过几代人的遗传而产生的.对于基因片段的分析有助于了解基因突变导致的遗传疾病.例如,如果一个基因序列中含有基因片段ATG,则可能含有某种遗传疾病.生物科学家们已经发现许多这类基因片段.对于已知的不安全的基因片段集合P,如果一个基因序列中含有P中基因片段,则称该基因序列为不安全的基因序列,否则称该基因序列为安全的基因序列.
算法设计:对于给定的不安全的基因片段集合P和一个正整数n,计算长度为n的安全的基因序列个数.
数据输入:由文件input.txt提供输入数据.文件的第1行有两个正整数n(1≤n≤2x109)和m(0≤m≤10).n是基因序列长度,m是不安全的基因片段个数.接下来的m行中,每行是一个长度不超过10的不安全的基因片段.每个文件可能有多个测试数据.
结果输出:将计算出的长度为n的安全的基因序列个数mod100000,输出到文件output.txt中.

问题描述:给定2个长度分别为n和m的序列x[0...n-1]和y[0...m-1],以及d个约束字符串![问题描述:给定2个长度分别为n和m的序列x[0...n-1]和y[0...m-1],以及d个约束字符](https://img2.soutiyun.com/ask/2021-01-05/978701034881386.png) 多子串排斥约束的最长公共子序列问题就是要找出x和y的不含为其子串的最长公共子序列
多子串排斥约束的最长公共子序列问题就是要找出x和y的不含为其子串的最长公共子序列
算法设计:设计一个算法,找出给定序列x和y的不含为其子串的最长公共子序列.
数据输入:重文件input.txt提供输入数据.文件的第1行中给出正整数d,表示约束字符串个数.接下来的2行分别给出序列x和y.最后d行的每行给出一个约束字符串.
结果输出:将计算出的x和y的不含为其子串的最长公共子序列输出到文件output.txt中.文件的第1行输出最长公共子序列.第2行输出最长公共子序列的长度.
![问题描述:给定2个长度分别为n和m的序列x[0...n-1]和y[0...m-1],以及d个约束字符](https://img2.soutiyun.com/ask/2021-01-05/97870111503397.png)
设有一个长度为S的字符串,其字符顺序存放在一个一维数组的第1至第S个单元中(每个单元存放一个字符)。现要求从此字符串的第m个字符以后删除长度为t的子串,m<s,t<(s-m),并将删除后的结果复制在该数组的第s单元以后的单元中,试设计此删除算法。
A.a+1表示的是字符t的地址
B.p指向另外的字符串时,字符串的长度不受限制
C.p变量中存放的地址值可以改变
D.a中只能存放10个字符
有以下程序: #include <string.h> main() { char p[]={'a','b','c'},q[10]={'a','b','c'}; printf("%d %d\n",strlen(p),strlen(q)); } 以下叙述中正确的是()。
A.在给p和q数组置初值时,系统会自动添加字符串结束符,故输出的长度都为3
B.由于p数组中没有字符串结束符,长度不能确定;但q数组中字符串长度为3
C.由于q数组中没有字符串结束符,长度不能确定;但p数组中字符串长度为3
D.由于p和q数组中都没有字符串结束符,故长度都不能确定
A.s数组长度和p所指向的字符串长度相等
B.s和p完全相同
C.*p与s[0]相等
D.数组s中的内容和指针变量p中的内容相等

















