 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[主观题]
己知某一混合物中包含N个组分,且其包含的各个组分的纯物质谱已知,若测得该系列混合物在L个分析
己知某一混合物中包含N个组分,且其包含的各个组分的纯物质谱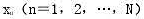 已知,若测得该系列混合物在L个分析通道处获得的分析信号为Y,设分析信号
已知,若测得该系列混合物在L个分析通道处获得的分析信号为Y,设分析信号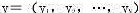 与样本中各组分的浓度
与样本中各组分的浓度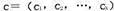 服从以下关系:
服从以下关系:
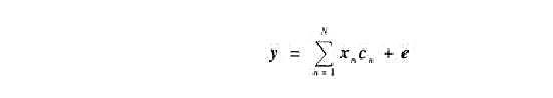
试估计该混合物中各组分的浓度(写出计算式)。
查看答案

 如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
己知某一混合物中包含N个组分,且其包含的各个组分的纯物质谱已知,若测得该系列混合物在L个分析通道处获得的分析信号为Y,设分析信号与样本中各组分的浓度服从以下关系:
试估计该混合物中各组分的浓度(写出计算式)。
如果结果不匹配,请 联系老师 获取答案
 更多“己知某一混合物中包含N个组分,且其包含的各个组分的纯物质谱已…”相关的问题
更多“己知某一混合物中包含N个组分,且其包含的各个组分的纯物质谱已…”相关的问题
A.顺序存储方式的优点是存储密度大,且插入、删除运算效率高
B.链表中的每一个结点都包含一个指针
C.包含n个结点的二叉排序树的最大检索长度为log/-2n
D.将一棵树转换为二叉树后,根结点没有右子树
A.n个变量的积项,它包含全部n个变量
B.n个变量的和项,它包含n个原变量
C.每个变量都以原、反变量的形式出现,且仅出现一次
D.n个变量的和项,它不包含全部变量
A.n个变量的积项,它包含全部n个变量
B.n个变量的和项,它包含n个原变量
C.每个变量都以原、反变量的形式出现,且仅出现一次
D.n个变量的和项,它不包含全部变量
试设计一个算法,利用T公司提供的m个补丁程序,将原软件修复成一个没有错误的软件,并使修复后的软件耗时最少.
算法设计:对于给定的n个错误和m个补丁程序,找到总耗时最少的软件修复方案.
数据输入:由文件input.txt提供输入数据.文件第1行有2个正整数n和m,n表示错误总数,m表示补丁总数(1≤n≤20,1≤m≤100).接下来m行给出了m个补丁的信息.每行包括一个正整数,表示运行补丁程序i所需时间以及2个长度为n的字符串,中间用个空格符隔开.在第1个字符串中,如果第k个字符bk为“+”,则表示第k个错误属于B1[i],若为“-”,则表示第k个错误属于B2[i],若为“0”,则第k个错误既不属于B1[i]也不属于B2[i],即软件中是否包含第k个错误并不影响补丁i的可用性.在第2个字符串中,如果第k个字符bk为“+”,则表示第k个错误属于F1[i],若为“-”,则表示第k个错误属于F2[i],若为“0”,则第k个错误既不属于F1[i]也不属于F2[i],即软件中是否包含第k个错误不会因使用补丁i而改变.
结果输出:将总耗时数输出到文件output.txt.如果问题无解,则输出0.


















