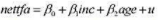题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[主观题]
数据集BWGHT.RAW包含了美国妇女生育方面的数据。我们关心的两个变量是因变量[婴儿出生体重的盎
司数(bwght)]和解释变量[母亲在怀孕期间平均每天抽烟的根数(cigs)].下面这个简单回归是用n=1388个出生数据进行估计的:
bwght=119.77-0.514cigs
(i)当cigs=0时,预计婴儿的出生体重为多少?当cigs=20(每天一包)时呢?评价其差别。
(ii)这个简单回归能够得到婴儿出生体重和母亲抽烟习惯之间的因果关系吗?请解释。
(iii)要预测出生体重125盎司,cigs应该为多少?
(iv)样本中在怀孕期间不抽烟的妇女比例约为0.85。这有助于解释第(iii)部分中的结论吗?
查看答案

 如果结果不匹配,请 联系老师 获取答案
如果结果不匹配,请 联系老师 获取答案

 更多“数据集BWGHT.RAW包含了美国妇女生育方面的数据。我们关…”相关的问题
更多“数据集BWGHT.RAW包含了美国妇女生育方面的数据。我们关…”相关的问题