 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[主观题]
(i)利用INJURY.RAW中肯塔基州的数据,从教材(13.12)中去掉afchnge后估计的方程为 交互项的估计
(i)利用INJURY.RAW中肯塔基州的数据,从教材(13.12)中去掉afchnge后估计的方程为 交互项的估计
(i)利用INJURY.RAW中肯塔基州的数据,从教材(13.12)中去掉afchnge后估计的方程为

交互项的估计值与式(13.12)中的估计值相当接近,这令人吃惊吗?请解释。
(ii)当包含afchnge而去掉highearn后结果是
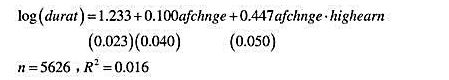
为什么现在交互项的系数远大于教材(13.12)中的系数?[提示:在方程(13.10)中,若β1=0,对处理组和对照组做的假定是什么?]
查看答案

 如果结果不匹配,请 联系老师 获取答案
如果结果不匹配,请 联系老师 获取答案

 更多“(i)利用INJURY.RAW中肯塔基州的数据,从教材(13…”相关的问题
更多“(i)利用INJURY.RAW中肯塔基州的数据,从教材(13…”相关的问题


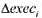 的哪个1统计量更值得信赖, 是通常的!统计量还是异方差-稳健的1统计量?为什么?
的哪个1统计量更值得信赖, 是通常的!统计量还是异方差-稳健的1统计量?为什么?















