 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[单选题]
设有如下函数定义,则函数返回的值是()。int*fun(inta[],intn){returna+n;}
A.数组元素a[n]的值
B.数组元素的下标
C.数组元素a[n]的地址
D.数组a的首地址
查看答案

 如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
A.数组元素a[n]的值
B.数组元素的下标
C.数组元素a[n]的地址
D.数组a的首地址
如果结果不匹配,请 联系老师 获取答案
 更多“设有如下函数定义,则函数返回的值是()。int*fun(in…”相关的问题
更多“设有如下函数定义,则函数返回的值是()。int*fun(in…”相关的问题
解决问题的一种方法是使用2-d树。2-d树类似于二叉搜索树,不同之处在于:
◇偶数层用keyl来比较:在该层上每一结点的keyl都大于共左子树中任一结点的key1,都不大于其右子树中任一结点的keyl。
◇奇数层用key2来比较:在该层上每一结点的key2都大于其左子树中任一结点的key2,都不大于其右子树中任一结点的key2.
◇树的根结点处于第0层。每次插入或搜索都从根结点出发,逐层比较。新结点应作为叶结点插入,
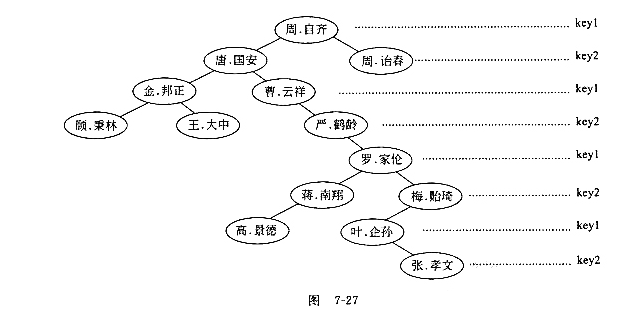
臂如,可以将不同人的姓和名(假设没有同名同姓者)分别为keyl和key2,建立一棵2-d树.作为例子,图7-27就是将清华大学的历任校长,按共任职年代的先后次序(周白齐、唐国安、周春、金邦正、曹云祥、严鹤龄、罗家伦、梅贻琦、叶企孙、蒋南翔、高景德、张孝文、王大中、顾秉林),顺序插人而形成的一棵2-d树。
(1)若命名树结点的类名为kdTNode,树的类名为kdTrce,关键码keyl的数据类型为T1,关键码key2的数据类型为T2,试写出2-d树的模板类结构定义,包括构造函数、复制构造函数、求树高、按给定值搜索、查找左子女、查找右子女、查找父结点、插人、删除等函数。此外,还要定义对树结点私有数据成员的存取函数(只要求写出函数的原型,不必给出代码实现)。
(2)基于上述定义,写出其中一个成员函数的实现代码:从根开始搜索关键码keyl和
key2与给定值vall和val2匹配的结点。函数的形式为:

若搜索成功,则函数返回true值,同时引用参数pt指向搜索到的结点,另引用参数pr指向结点*pt的父结点。此时,若树中只有一个结点,pr为NULL。
若搜索不成功或树为空,则函数返回false值,同时参数pt为NULL,在树非空时,pr则指向搜索失败前指针pt最后到达的结点;当树为空时,pr为NULL。

A.x.a
B.x.a()
C.x->GetValue()
D.x.GetValue()
(1)用cerr<<及exit(1)语句来终止执行并报告错误;
(2)用返回布尔值false,true来实现算法,以区别是正常返回还是错误返[回;
(3)在函数的参数表设置一个引用型的整型变量来区别是正常返回还是某种错误返回。
试讨论这3种方法各自的优缺点,并以你认为是最好的方式实现它。
A.函数调用时传入的参数称为实参
B.函数定义时给出的参数称为形参
C.形参和实参可以同名
D.在函数体中修改形参,则相应实参的值也会改变
针对带附加头结点的单链表,试编写下列函数。
(1)定位函数Locate:在单链表中寻找第i个结点。若找到,则函数返回第i个结点的地址;若找不到,则函数返回NULL。
(2)求最大值函数max:通过一趟遍历在单链表中确定值最大的结点,
(3)统计函数number:统计单链表中具有给定值x的所有元素,
(4)建立函数create:根据一维数组aLn]建立一个单链表,使单链表中各元素的次序与a[n]中各元素的次序相同,要求该程序的时间复杂度为O(n)。
(5)整理函数tidyup:在非逆减有序的单链表中删除值相同的多余结点。

















