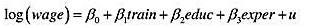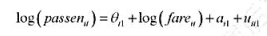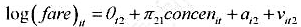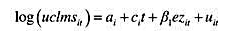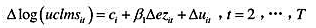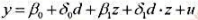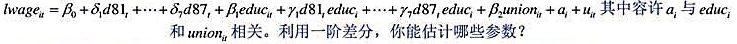克(Papke,2005)所用的学校层次数据相似。这个方程中我们关注的因变量是math4,即一个学区四年级学生通过数学标准化考试的百分数。主要的解释变量是rexpp,即学区平均每个学生的真实支出,以1997年的美元计。支出变量以对数形式出现。
(i)考虑静态非观测效应模型

其中,enrolit表示学区总注册学生人数,lunchit表示学区中学生有资格享受学校午餐计划的百分数。(因此lunchit是学区贫穷率的一个相当好的度量指标。)证明:若平均每个学生的真实支出提高10%,则math4it约改变β1/10个百分点。
(ii)利用一阶差分估计第(i)部分中的模型。最简单的方法就是在一阶差分方程中包含一个截距项和1994~1998年度虚拟变量。解释支出变量的系数。
(iii)现在,在模型中添加支出变量的一阶滞后,并用一阶差分重新估计。注意你又失去了一年的数据,所以你只能用始于1994年的变化。讨论即期和滞后支出变量的系数和显著性。
(iv)求第(iii)部分中一阶差分回归的异方差-稳健标准误。支出变量的这些标准误与第(iii)部分相比如何?
(v)现在,求对异方差性和序列相关都保持稳健的标准误。这对滞后支出变量的显著性有何影响?
(vi)通过进行一个AR(1)序列相关检验,验证差分误差rit=Δuit含有负序列相关。
(vii)基于充分稳健的联合检验,模型中有必要包含学生注册人数和午餐项目变量吗?
 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
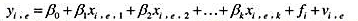


 如果结果不匹配,请 联系老师 获取答案
如果结果不匹配,请 联系老师 获取答案

 更多“考虑一个雇员水平的模型 其中无法观测变量f是在一个给定的企业…”相关的问题
更多“考虑一个雇员水平的模型 其中无法观测变量f是在一个给定的企业…”相关的问题
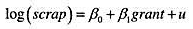
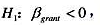 它在5%的显著性水平上统计显著吗?
它在5%的显著性水平上统计显著吗?