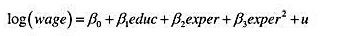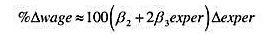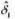题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[主观题]
使用WAGE1.RAW中的数据。 (i)求出样本中的平均受教育程度。最低和最高受教育年数是多少? (ii)
使用WAGE1.RAW中的数据。
(i)求出样本中的平均受教育程度。最低和最高受教育年数是多少?
(ii)求出样本中的平均小时工资。它看起来是高还是低?
(iii)工资数据用1976年的美元报告。利用(2004年或以后的)《总统经济报告》,求出并报告1976年和2003年的消费者价格指数(CPI)。
(iv)利用第(iii)部分中的CPI值,求以2003年美元度量的平均小时工资。现在,平均小时工资看起来合理了吗?
(v)样本中有多少女人和男人?
查看答案

 如果结果不匹配,请 联系老师 获取答案
如果结果不匹配,请 联系老师 获取答案

 更多“使用WAGE1.RAW中的数据。 (i)求出样本中的平均受教…”相关的问题
更多“使用WAGE1.RAW中的数据。 (i)求出样本中的平均受教…”相关的问题