

 如果结果不匹配,请
如果结果不匹配,请 
 更多“线性回归通常可使用最小二乘法、极大似然估计等方法得到最优参数…”相关的问题
更多“线性回归通常可使用最小二乘法、极大似然估计等方法得到最优参数…”相关的问题
A.α-β剪枝技术
B.A*算法
C.最小二乘法
D.线性回归
A.估计量具有唯一性
B.估计量可以有不同的表达式
C.矩估计和极大似然估计得到的估计量一定是不同的
D.矩估计得到的估计量总是优于极大似然估计
E.在已知总体分布信息的情况下矩估计一般不如极大似然估计好
使用SMOKE.RAW中的数据。
(i)变量cigs是平均每天抽烟的数量。样本中有多少人根本就不抽烟?有多大比例的人声称每天抽20支?你为什么认为抽20支香烟的人会有所堆积?
(ii)给定你对第(i)部分的回答,cigs看起来具有条件泊松分布吗?
(iii)用log(cigpric)、log(income)、white、educ、age和age2作为解释变量,估计cigs的一个泊松回归模型。估计的价格和收入弹性是多少?
(iv)利用极大似然标准误,价格和收入变量在5%的水平上统计显著吗?
(v)求方程(17.35)后面介绍的σ2估计值。σ是多少?你应该如何调整第(iv)部分中的标准误?
(vi)利用第(v)部分中调整后的标准误,价格和收入弹性现在统计显著异于零吗?请解释。
(vii)利用更稳健的标准误,教育和年龄变量显著吗?你如何解释educ的系数?
(viii)求泊松回归模型的拟合值yi。找出最大值和最小值,并讨论指数模型对瘾君子的预测表现。
(ix)利用第(viii)部分的拟合值,求yi和yi之相关系数的平方。
(x)使用第(iii)部分中的解释变量(及相同的函数形式),用OLS估计cigs的一个线性模型。线性模型和指数模型哪个拟合得更好?两者的R都很大吗?
利用CHARITY.RAW中的数据回答如下问题
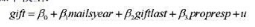
(i)用普通最小二乘法估计如下模型:
按照通常的方式报告估计方程,包括样本容量和R²。其R²与不使用giftlast和propresp的简单回归所得到的R²相比如何?
(ii)解释mailsyear的系数,它比对应的简单回归系数更大还是更小?
(iii)解释propresp的系数,千万要注意propresp的度量单位。
(iv)现在,在这个方程中增加变量avggif。这将对mailsyear的估计效应造成什么样的影响?
(v)在第(iv)部分的方程中,giftlast的系数有何变化?你认为这是怎么回事?
在例9.1中,我们narr86在的一个线性模型中增加二次项pcrv2、ptime86²和inc 862。
(i)利用CRIME L RAW中的数据, 在例17.3的泊松回归中同样增加这些项。
(ii)根据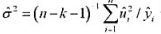 估计 。数据存在过度散布的证据吗?该如何调整泊松极大似然估计标准误?
估计 。数据存在过度散布的证据吗?该如何调整泊松极大似然估计标准误?
(iii)利用第(i)部分和第(ii)部分的结论及教材表17.3,计算这三个平方项联合显著性的准似然比统计量。你得到什么结论?
















