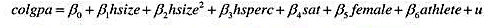题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[主观题]
(i)对于一个二值响应y,令表示样本中1的比例(等于yi的样本均值)。令q0,表示结果为y=0的
(i)对于一个二值响应y,令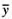 表示样本中1的比例(等于yi的样本均值)。令q0,表示结果为y=0的正确预测百分数,而q1表示结果为y=1的正确预测百分数。若p是整体的正确预测百分数,证明p是q0和q1的一个加权平均:
表示样本中1的比例(等于yi的样本均值)。令q0,表示结果为y=0的正确预测百分数,而q1表示结果为y=1的正确预测百分数。若p是整体的正确预测百分数,证明p是q0和q1的一个加权平均:
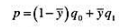
(ii)在一个容量为300的样本中,假设yi=0.70,所以有210个结果为yi=1,90个结果为yi=0。假设yi=0的正确预测百分数为80,而yi=1的正确预测百分数为40。求总体正确预测百分数。
查看答案

 如果结果不匹配,请 联系老师 获取答案
如果结果不匹配,请 联系老师 获取答案

 更多“(i)对于一个二值响应y,令表示样本中1的比例(等于yi的样…”相关的问题
更多“(i)对于一个二值响应y,令表示样本中1的比例(等于yi的样…”相关的问题
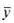 表示样本中1的比例(等于yi的样本均值)。令
表示样本中1的比例(等于yi的样本均值)。令 表示结果为y=0的正确预测百分数,而
表示结果为y=0的正确预测百分数,而 表示结果为y=1的正确预测百分数。若
表示结果为y=1的正确预测百分数。若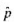 是整体的正确预测百分数,证明
是整体的正确预测百分数,证明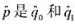 的一个加权平均:
的一个加权平均:
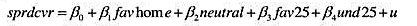
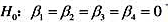 下,模型中不存在异方差性。
下,模型中不存在异方差性。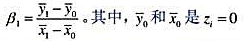 的那部分样本中yi和xi的样本平均值,而
的那部分样本中yi和xi的样本平均值,而 的样本平均值。该估计量称为群组估计量,它是由沃德(Wald,1940)最先提出。
的样本平均值。该估计量称为群组估计量,它是由沃德(Wald,1940)最先提出。

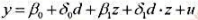

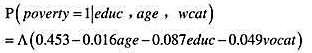
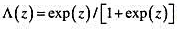 为逻辑斯蒂函数。对于一个具有12年教育经历的40岁的人来说,高中阶段受到过职业培训对其目前生活在贫困中的影响是什么?这个影响大吗?
为逻辑斯蒂函数。对于一个具有12年教育经历的40岁的人来说,高中阶段受到过职业培训对其目前生活在贫困中的影响是什么?这个影响大吗?