题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[主观题]
使用VOTE1.RAW中的数据。 (i)估计一个以voteA为因变量并以prystrA、deocA、log(expendA)和log(ex
使用VOTE1.RAW中的数据。
(i)估计一个以voteA为因变量并以prystrA、deocA、log(expendA)和log(expendB)为自变量的模型。得到OLS残差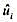 ,并将这些残差对所有的自变量进行回归。解释你为什么得到R2=0。
,并将这些残差对所有的自变量进行回归。解释你为什么得到R2=0。
(ii)现在计算异方差性的布罗施-帕甘检验。使用F统计量的形式并报告P值。
(iii)同样利用F统计量形式计算异方差性的特殊怀特检验。现在异方差性的证据有多强?
查看答案

 如果结果不匹配,请 联系老师 获取答案
如果结果不匹配,请 联系老师 获取答案

 更多“使用VOTE1.RAW中的数据。 (i)估计一个以voteA…”相关的问题
更多“使用VOTE1.RAW中的数据。 (i)估计一个以voteA…”相关的问题