 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[主观题]
利用计量经济软件中的“聚类”选项,便得到教材表14-2中混合OLS估计值充分稳健[即对复合误差(vi
利用计量经济软件 中的“聚类”选项,便得到教材表14-2中混合OLS估计值充分稳健[即对复合误差(vit:t=1,···,T)中的序列相关和异方差性保持稳健]的标准误为:
中的“聚类”选项,便得到教材表14-2中混合OLS估计值充分稳健[即对复合误差(vit:t=1,···,T)中的序列相关和异方差性保持稳健]的标准误为:
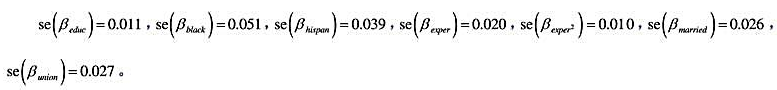
(i)这些标准误与非稳健标准误相比一般如何?为什么?
(ii)混合OLS的稳健标准误与RE的标准误相比如何?解释变量是否随时间变化有什么关系吗?
查看答案

 如果结果不匹配,请 联系老师 获取答案
如果结果不匹配,请 联系老师 获取答案

 更多“利用计量经济软件中的“聚类”选项,便得到教材表14-2中混合…”相关的问题
更多“利用计量经济软件中的“聚类”选项,便得到教材表14-2中混合…”相关的问题
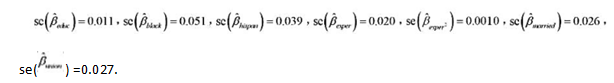


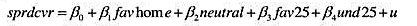
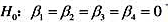 下,模型中不存在异方差性。
下,模型中不存在异方差性。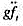 。
。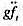 对教材方程(10.35)中所有变量(包括t和t2)回归。比较得出的R²与教材方程(10.35)中的R2有何不同。你有何结论?
对教材方程(10.35)中所有变量(包括t和t2)回归。比较得出的R²与教材方程(10.35)中的R2有何不同。你有何结论?















