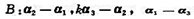题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[主观题]
假设有k个关键码值互为同义词,若用线性探查法把这k个关键码值存人散列表中,至少要进行()次探查。
假设有k个关键码值互为同义词,若用线性探查法把这k个关键码值存人散列表中,至少要进行()次探查。
A、k-1
B、K
C、k+1
D、k(k+1)/2
查看答案

 如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
A、k-1
B、K
C、k+1
D、k(k+1)/2
如果结果不匹配,请 联系老师 获取答案
 更多“假设有k个关键码值互为同义词,若用线性探查法把这k个关键码值…”相关的问题
更多“假设有k个关键码值互为同义词,若用线性探查法把这k个关键码值…”相关的问题
(1)搜索失败;
(2)搜索成功,且表中只有一个关键码等于给定值k的元素;
(3)搜索成功,且表中有若千个关键码等于给定值k的元素,要求一次搜索找出所有元素。
(I)利用I型线性相位滤波器的幅度函数的特性
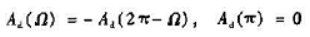
试证明II型线性相位滤波器在M+1个取样点值满足
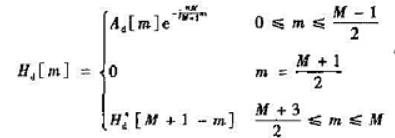
(2)试推导h[k]的表达式,并证明h[k]满足线性相位条件。
对(许多美国工人可用的)401(k)养老金计划的出现是否提高了净储蓄,吸引了大量研究兴趣。数据集401KSUBS.RAW包含了有关净金融资产(nettfa)、家庭收入(ic)、是否有资格参与401(k)计划的二值变量(e401k)和其他几个变量的信息。
(i)样本中有资格参与一个401(k)计划的家庭比例是多少?
(ii)估计一个用收入、年龄和性别解释401(k)资格的线性概率模型。包括收入和年龄的二次项,并以通常形式报告结论。
(iii)你认为401(k)资格独立于收入和年龄吗?性别呢?请解释。
(iv)求第(ii)部分中估计的线性概率模型的拟合值。有小于0或大于1的拟合值吗?
(v)利用第(iv)部分中的拟合值e401k1,定义e401k1在e401k≥0.5时取值1,并在2e401k<0.5时取值0。在9275个家庭中,预计有多少家庭有资格参与401(k)计划?
(vi)对于没有资格参加401(k)的5638个家庭,利用预测值e401k1,预测其中有多大比例没有401(k)?对于有资格参加401(k)的3637个家庭,其中有多大比例的家庭有401(k)?(如果你的计量经济软件具有“制表”命令更好。)
(vii)总正确预测比约为64.9%。给定第(vi)部分的答案,你认为这是模型好坏的一个完备描述吗?
(viii)在线性概率模型中增加一个解释变量pira。其他条件不变,若一个家庭有某人拥有个人退休金账户,一个家庭有资格参与401(k)计划的估计概率会提高多少?在10%的显著性水平上,它统计显著异于0吗?
解决问题的一种方法是使用2-d树。2-d树类似于二叉搜索树,不同之处在于:
◇偶数层用keyl来比较:在该层上每一结点的keyl都大于共左子树中任一结点的key1,都不大于其右子树中任一结点的keyl。
◇奇数层用key2来比较:在该层上每一结点的key2都大于其左子树中任一结点的key2,都不大于其右子树中任一结点的key2.
◇树的根结点处于第0层。每次插入或搜索都从根结点出发,逐层比较。新结点应作为叶结点插入,
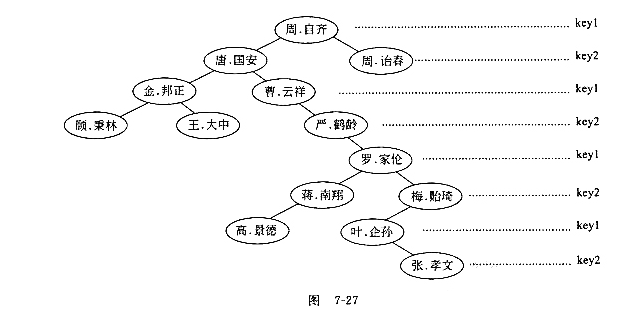
臂如,可以将不同人的姓和名(假设没有同名同姓者)分别为keyl和key2,建立一棵2-d树.作为例子,图7-27就是将清华大学的历任校长,按共任职年代的先后次序(周白齐、唐国安、周春、金邦正、曹云祥、严鹤龄、罗家伦、梅贻琦、叶企孙、蒋南翔、高景德、张孝文、王大中、顾秉林),顺序插人而形成的一棵2-d树。
(1)若命名树结点的类名为kdTNode,树的类名为kdTrce,关键码keyl的数据类型为T1,关键码key2的数据类型为T2,试写出2-d树的模板类结构定义,包括构造函数、复制构造函数、求树高、按给定值搜索、查找左子女、查找右子女、查找父结点、插人、删除等函数。此外,还要定义对树结点私有数据成员的存取函数(只要求写出函数的原型,不必给出代码实现)。
(2)基于上述定义,写出其中一个成员函数的实现代码:从根开始搜索关键码keyl和
key2与给定值vall和val2匹配的结点。函数的形式为:

若搜索成功,则函数返回true值,同时引用参数pt指向搜索到的结点,另引用参数pr指向结点*pt的父结点。此时,若树中只有一个结点,pr为NULL。
若搜索不成功或树为空,则函数返回false值,同时参数pt为NULL,在树非空时,pr则指向搜索失败前指针pt最后到达的结点;当树为空时,pr为NULL。
(1)画出描述上述查找过程的判定树。
(2)计算等搜索概率下搜索成功的平均搜索长度。
(3)计算等搜索概率下搜索不成功的平均搜索长度。
算法设计:对任意给定的整数n和k,以及完成任务i需要的时间为ti(i=1,2,...,n).设计一个优先队列式分支限界法,计算完成这n个任务的最佳调度.
数据输入:由文件input.txt给出输入数据.第1行有2个正整数n和k.第2行的n个正整数是完成n个任务需要的时间.
结果输出:将计算的完成全部任务的最早时间输出到文件output.txt.

A、顺序搜索
B、折半搜索
C、前两者都不正确







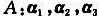 线性无关,当k取何值时向量组
线性无关,当k取何值时向量组